<요약>
기존에는 일상 대화 시나리오를 수집하기 위해서 많은 인력이 투입되어 오랫동안 수작업으로 대화시나리오를 구축하는 작업을 진행하였다. 또한, 이렇게 대화 시나리오를 구축하여 시스템에서 운용한다고 하더라도, 최소한 6개월 이상이 소요되므로 이미 과거 6개월 이전 대화를 진행하는 문제가 있다.
따라서, 본 연구는 최대한 빠르게 일상 대화 시나리오를 구축하여, 현재 트랜드가 반영된 대화를 진행하고자 하며, 이를 위해서 동영상에 포함된 대화 시나리오를 추출하는 방법을 연구하였다.
제 1 장 서 론
1.1 연구 배경
최근 AI 스피커, AI 음성 비서 등 음성 대화 인터페이스를 활용한 다양한 제품이 출시되고 있다. 이러한 제품에서 다양한 일상 대화를 구사하기 위해서는 일상 대화 시나리오 DB가 필요하며, 가능한 다양한 분야를 대상으로 다양한 주제에 대한 대화를 진행해야 한다.
과거 일상 대화 시나리오 수집을 위해서는 설문조사, 녹취, SNS 크롤링 등 다양한 방법이 수행되어 왔다. 그러나, 최근 유튜브, 트위치 등 새로운 동영상 플랫폼이 출시되면서 사용자들의 커뮤니케이션 수단이 변화되고 있으며, 각종 동영상이 양질의 대화 시나리오를 포함하고 있어서, 이 동영상에서 대화 시나리오를 쉽게 추출할 필요성이 증가하고 있다.
1.2 관련연구
기존 SNS를 통한 시나리오 데이터 수집에 대한 연구가 진행되었다[1]. SNS를 통한 시나리오 수집은 다양한 주제에 대한 시나리오를 수집할 수 있다는 장점이 있지만, 실제 사람이 말로 표현하는 ‘구어체’가 아닌 문장에서 사용하는 ‘문어체’가 사용된 경우가 대다수이다. 따라서 대화 시나리오로 사용하기 위해서는 ‘문어체’ 문장을 ‘구어체’ 문장으로 수정해야하는 번거로움이 있다. 하지만 동영상에서 추출한 시나리오는 실제 사람이 대화를 하거나 설명을 하는 등 다양한 상황에서 ‘구어체’로 발화하는 문장이기 때문에 상대적으로 정제 작업이 수월한 측면이 있다.
제 2 장 본 론
2.1 전체 시스템 프로세스
전체 시스템은 프로세스는 그림 1과 같다. 본 시스템은 먼저 동영상을 촬영하고 동영상에서 오디오 음성을 추출한다. 그리고 추출된 음성에서 프레임 단위로 ZCR(Zero Crossing Rate)를 계산한다. 그 후 신호값의 범위를 정규화하고, Mahalanobis Distance를 계산하며, 음성구간별 ZCR값으로 끝점을 검출한다. 그렇게 검출된 끝점을 통해 음성 데이터를 문장 별로 구분하고, 각 문장을 연속된 대화 시나리오로 구성한다. 테스트에는 “안녕하세요. 마이크 테스트 중입니다.”라고 발화한 mp4 동영상 파일을 사용했다. 동영상의 길이는 8.704초이다.

시스템에서 동영상 파일은 스마트폰, 태블릿, 디지털 카메라 등으로 촬영된 mp4 확장자를 가진 동영상 파일을 사용한다. mp4 확장자의 동영상 파일이 들어오면 동영상에서 오디오 데이터만 추출되는데, 추출된 데이터는 wav 파일 확장자를 가지며, 모노 채널의 16,000샘플링레이트를 가진다.

2.3 ZCR 계산
먼저 시스템은 녹화된 동영상에서 오디오 음성을 추출한다. 그렇게 추출된 음성은 모노 채널, wav파일, 16,000 샘플링레이트를 가지는 오디오 파일로 변환된다. 음성 끝점 검출을 위한 첫 번째 단계로 ZCR(Zero Crossing Rate)를 계산한다. ZCR은 영교차율로도 부르며 신호 값이 0을 지나는 즉 신호의 부호가 바뀌는 비율을 말한다. 테스트에 사용한 영상은 총 139,263개의 샘플을 가지는데 이는 1프레임 당 250개의 샘플이 포함됨을 보여준다. ZCR은 1프레임 당 각각 계산하여 나타내는데, 이를 그래프로 표현하면 그림 3과 같다.

계산된 ZCR 값에 따라 일정값보다 크면 프레임별 버퍼에 1값을 저장하고, 그렇지 않을 경우 0을 저장한다. 이 버퍼의 값은 추후 끝점검출의 시작 프레임 위치 계산에 사용된다.
2.4 신호값 정규화
끝점검출 알고리즘에서 계산의 편의성을 위해 신호값(에너지)를 정규화 한다. 정규화는 오디오 파일의 전체 구간에서 최대값을 구한 후, 각 신호값을 최대값으로 나누어 준다. 그렇게 정규화된 신호값을 통해 음성구간, 무음구간을 계산한다.

2.5 유성음 구간, 무성음 구간(소음 구간) 디텍션
유성음 구간, 무성음 구간 계산을 위해 최초 20프레임 구간을 무성음 구간(소음 구간)으로 설정하고 표준편차를 계산한다. 표준편차를 계산하기 위해 우선 최초 20프레임(5000샘플)의 신호값을 모두 더한 뒤, 최초 20프레임의 샘플 수로 나누어 평균을 구한다. 그리고 각 샘플에서 평균값을 뺀 값의 제곱을 5000샘플에 대해 모두 계산 한 뒤 합해서 분산을 구한다. 계산된 분산 값의 제곱근을 계산하여 최종적으로 표준편차 값을 구한다. 이렇게 구해진 표준편차 값은 영상의 모든 구간에 대해 20프레임 구간에 대해 마할라노비스 거리를 계산하여 음성 구간을 추출한다.
마할라노비스 거리는 평균과의 거리가 표준편차의 몇 배인지 나타내는 값으로, 앞서 구한 첫 20프레임 구간의 표준편차와의 거리를 각 샘플 별로 영상의 처음부터 끝까지 계산하면서 특정 샘플에서 마할라노비스 거리(Mahalanois Distance)가 특정 임계치를 넘는 경우 유성음 샘플로 판단하고, 임계치를 넘지 못하는 경우 무성음 샘플로 판단한다.

2.6 끝점 검출
2.4절에서 계산된 각 샘플별 마할라노비스 거리값을 이용해서 각 프레임 별로 보이스 유성음샘플의 수와 무성음 샘플의 수를 계산한다. 마할라노비스 거리값이 임계치를 넘는 경우 유성음 개수를 증가시키고, 그렇지 않은 경우에는 무성음 개수를 증가시킨다.
프레임 별로 무성음 샘플보다 유성음 샘플의 개수가 많고, ZCR 값이 0보다 큰 경우 끝점검출 시작 프레임으로 설정한다.
그리고 앞 절에서 계산된 끝점 검출 시작 프레임 위치로부터 일정 프레임 이상 진행되고, 무음 구간이 일정 거리 이상이 될 경우 해당 프레임을 문장의 끝나는 프레임으로 설정한다.
위 프로세스로 계산된 음성 구간은 그림 6과 같다.

2.7 대화 시나리오 추출
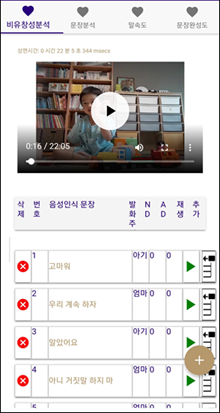
끝점 검출 후, 음성인식을 수행하며, 음성인식이 수행된 결과는 다음 그림과 같다. 동영상에서 아동과 엄마가 번갈아가며 음성 대화를 진행하고, 해당 대화가 진행된 음성구간을 디텍션한 뒤, 음성인식하여 대화 시나리오를 추출한다.
제 3 장 결 론
본 연구는 동영상으로부터 음성을 디텍션하여 대화 시나리오를 자동으로 추출하기 위한 연구이다. Mahalanobis Distance와 ZCR을 이용하여 동영상으로부터 음성을 디텍션하는 알고리즘을 개발하였으며, 이 알고리즘을 이용하여 동영상에서 대화시나리오를 추출하는 방법을 도출하였다.
본 연구를 통해서 기존 SNS 뿐만 아니라, 대용량 동영상에서도 다양한 주제를 포함한 대화시나리오를 추출하는 방법을 도출하였으며, 이 방법을 이용하여 대화시나리오 추출 속도를 향상 시킬 수 있었다.
인공지능 음성, 언어, 영상 분석/처리 전문기업 bory.io/
bory@bory.io




최근댓글